A Reliable web scraping Robot – Architectural Insights
Developing a robust scraping solution requires handling many moving parts due to reliability issues intrinsic to the solution – Network traffic issues, frequent site content changes, and blockers. A reliable system shall give good visibility into the solution’s day-to-day operations, self-heal the transient errors, and provide tools to handle permanent errors.
The diagram given below outlines a minimally viable solution for building a production-grade scraping robot. The proposed architecture cleanly decouples activities using a message broker, which results clean code and good operations visibility into the system.
Scraping Robot Solution - Generic Architecture
One can take open-source components to build the proposed solution. Some of the elements are RabbitMQ, BeautifulSoup, Scrapy, MongoDB, influx dB, Postgress, Nagios, and Python-Django. The rest of the document will discuss the Architecture and essential components required to deploy a scraping solution using AWS cloud-native resources.
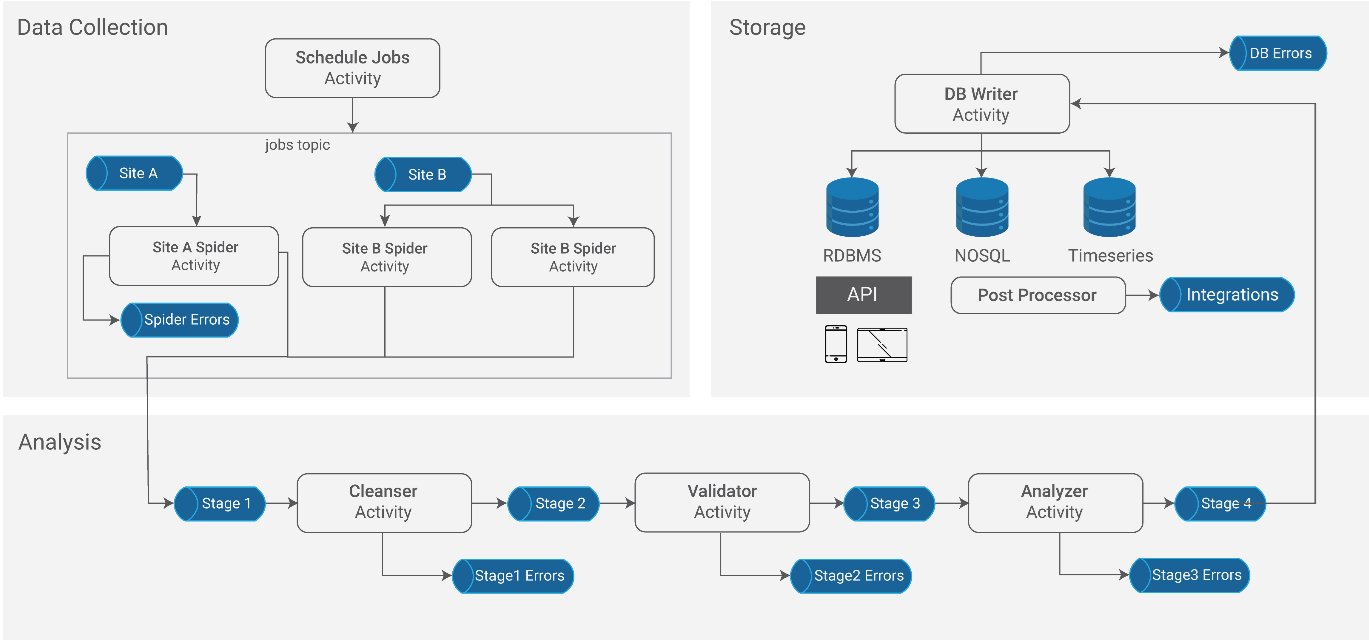
Scraping Robot Solution - AWS Architecture

Components
A spider is responsible for scraping the required contents of a targeted website. Refer to A reliable web scraping robot – design Insights for more details on spider development. Designing a configurable spider with the following options will reduce unnecessary network blockages and improve the overall spider reliability.
- Compliancy: Honor or ignore robots.txt
- Concurrency: How many spiders can concurrently scrape the target.
- Timeouts: Set the max time that a spider can run in a single execution. Also, set the minimum time interval between two consecutive scrapes.
- Retries: # retries and the retry interval, when a spider could not complete the job due to slow response or no response.
- Maximum payload: This is an ordinal number defining the maximum amount of work that a spider can do in a scrape attempt. Let the spider decide how to use this metric. Ex: max. #of products, or max # of consumer reviews.
- Session Capture: Provide an option to capture a video of the scraping session.
A Scheduler is responsible for scheduling scraping jobs and publish them to Jobs topic. The spiders that subscribed to this topic will pick up these jobs and scrape the specified sites. The schedular may also reschedule transient spider errors. A typical scheduler wakes up every five minutes and:
- Look at spider configurations and schedule jobs according to the periodicity defined for each spider.
- Consume messages from SpiderErrors queue, and reschedule new jobs for the items having temporary errors – Sites that are slow or not responding.
- Alert operations team about jobs that failed after max retry limit.
- Alert operations team when a spider encounters permanent errors such as unexpected content.
Analysis and storage activities vary from business case to business case, and the discussion about these activities is beyond the scope of this document. Refer to our recent article, A reliable web scraping robot – design Insights, for little more details on this subject.
A launcher is responsible for setting up the infrastructure and updating changes to the software components. The launcher will setup Topics, Queues, Lambda functions and subscriptions. The launcher program can be used as a command-line program or embedded in a CI/CD pipeline. The launcher is responsible for:
- Create the infrastructure using a cloud formation template or similar tools.
- Check out the source code using specified build id, deploy lambda functions, and establish subscriptions.
- Smoke - test the new deployment and verify the result.
- Send launch report to the operations team.
Conclusion
The Architecture emphasizes error recovery and flexible workflow by choosing Lambda and SQS. Using Lambda functions for scraping and result processing will simplify the deployment and offer maximum flexibility to workflow changes.
First-time scraping of a new site may become a bit tedious chore due to 15 min max time limit on Lambda functions. One may consider using ECS/MQ instead of Lambda/SQS for large implementations.
Even though, One can use the AWS console to manage day-to-day operations, building an operations UI with real-time dashboards will give better control to the Ops team.
About Mobigesture
Mobigesture has delivered text mining and analytical data visualization solutions to customer care, skincare and hospitality industries. Our team is proficient in scraping spiders, cloud-native resources, back-office integrations, NLP, predictive & deep learning, big data, AWS, Azure, GCP, Python Django/Flask, NodeJS, MongoDB, Elastic Search, React, Angular, D3, and Mobile Hybrid frameworks.
For any demos or POCs, please write to us at contact@mobigesture.com and know more about our offerings.