
People having oily skin and living in sub-tropical regions do not like our exfoliant products.
Our restaurant located in Scottsdale, Arizona, frequently has hygiene issues - dirty bathrooms or unclean tables - over the weekends.
N-gram analysis will help you make the above conclusions from your consumer reviews. It is the most straightforward analysis technique for text mining and natural language processing. N-gram model is a probabilistic model for predicting the Markov condition that the probability of a word's occurrence in a sentence depends upon its previous word. While it is the most efficient approximation method, Markov models do not capture the language's semantic aspects. So, this model is weak in handling out-of-vocabulary words.
The Approach
A consumer review generally conveys the user's opinion of a product, a service, or a brand; It talks about the positives, negatives, benefits, or how it caused damage to a person. We observed that people, in general, use common sentence structures to express their feelings, usually in a pattern-like manner by which we can capture the intent and motives of a consumer. Our research has revealed that in about 60% of cases, people say 'I will recommend' in 28 different ways and 'My skin feels good' in 20 different ways. Exploiting these speech patterns is key to our approach to the review analysis.
We developed unigram, bigram, trigram, and quadrigram models for consumer reviews. We found out that bigram and trigram models are the most effective ones for extracting consumer behavior, product usage, product issues, brand loyalty, and fake sales.
The rest of the discussion is about four significant activities involved in developing a review analysis system - Stemming & lemmatization, bigram, trigram pattern preparation, and result processing. We limit the discussion scope to the crucial activities and not discuss the entire review analyzer engine development.
We have collected consumer reviews of skincare products using a web scraping robot from different e-commerce portals and skincare blogs. Refer to our article A web scraping Robot – Architecture Insights for more details about scraping.
Consumer reviews have typos, grammar mistakes, slang words, oral English words, and incomplete or unrelated sentences. The data must go through several stages of cleaning to improve the accuracy of text processing. The following are the minimal data cleanup activities:
- Convert text to lower case and remove non-printable characters.
- Correct misspelled words using relevant misspelled corpora such as Cornell Univ. arXivLabs Github typo corpus or Birbeck Univ. corpora of misspellings.
- Use Porter stemmer algorithm to stem suffixes. Use nltk.stem.PorterStemmer to accomplish the task.
Example: Original Text => After stemming
I am recommending these products => I am recommend these product - Remove certain adjectives - Demonstrative(this), Distributive (every), and Possessive(you) - and articles. One can start with nltk.stopwords as a baseline list and improve the corpus during the trigram and bigram pattern generation process.
Example: I am recommend these product => I am recommend product - Bring negative Contraction words – ain't, didn't,… - to a base form 'not'.
Ex: I wouldn't recommend the product => I not recommend product - Bring 'be' form verbs and positive contractions to its base form 'be'.
Ex: am, are, is, have, I'll… => be
By defining bigram patterns and matching them with the review corpus, one can extract the reviewer's attributes (Skin type, eating preference) that are important for advanced analysis. Pattern generation is a manual and repetitive process and varies from business to business. For Instance, a personal care review's jargon is significantly different from that used in the hospitality segment.
- An analyst will sift through the corpus, identify text patterns that describe the reviewer attributes and prepare an attribute and bigram (2 words) map. The table given below depicts a sample map.
- The analyst will feed a new map into the analyzer and prepare two lists - a list of positive reviews (match found) for an attribute and a list of negative (match not found) reviews.
- The analyst will sample two hundred reviews from the negative list, isolate false-negative cases due to a missing bigram. Calculate a hit-ratio = # false-negative reviews / 200.
- Regenerate new bigrams to cover the false-negative cases and repeat the process until the hit-ratio exceeds 60%+
Attribute to Bigram Map
| Attribute | Review text | Bigram words |
|---|---|---|
| Skin-type = sensitive skin | I have a sensitive skin | 'sensitive', 'skin' |
| Skin-type = sensitive skin | My skin is sensitive | 'skin' 'sensitive.' |
| Eating-preference: soup | I prefer soup for my dinner | 'prefer', 'soup' |
Using trigram patterns, one can extract the reviewer's emotions and feelings from the review corpus. The trigram generation process is similar to the Bigram generation process, except the map contains the reviewer's emotions and trigrams (3 words). Here are sample maps
Emotion: I will recommend the product.
| Review Text | Trigram words |
|---|---|
| I would highly recommend the product | 'be', 'highly', 'recommend' |
| I will recommend the product to anyone | 'recommend', 'product', 'anyone' |
Emotion: It is a counterfeit product
| Review Text | Trigram words |
|---|---|
| It is not a real product | 'not', 'real', 'product' |
| The product did not have the safety seal | 'not', 'safety', 'seal' |
| It is not the original product | 'not', 'original', 'product' |
| product received, but not in its original box | 'not', 'original', 'box' |
Occasionally, one may need to develop bigrams to capture the emotions of a reviewer. Example: A review text' I don't recommend' => not, recommend'). Also, I learned to avoid the subject clause (I, we) in trigrams.
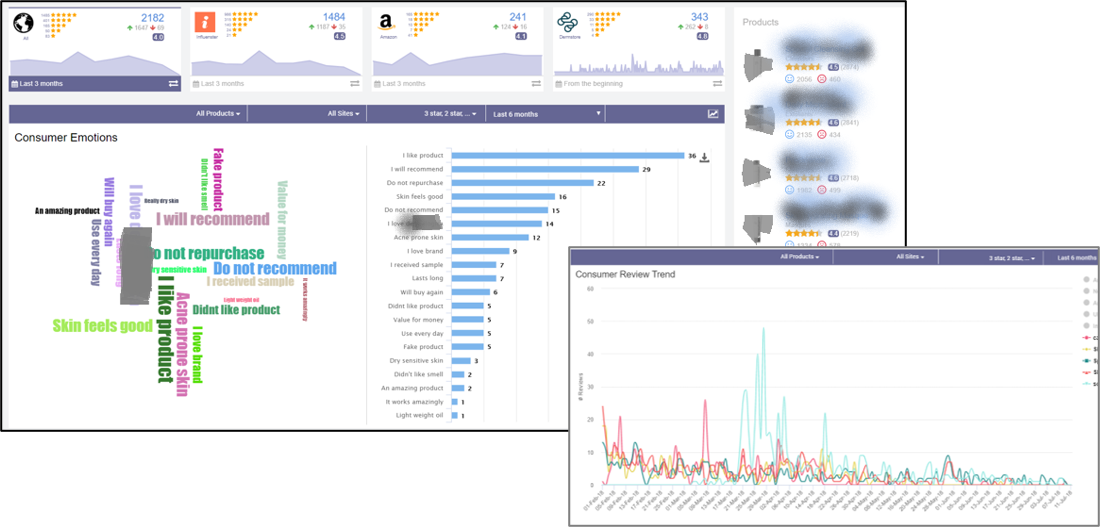
An interactive dashboard to visualize review analysis results will help companies understand product issues, marketing campaign effectiveness, fake product sales, and customer issues. For Instance, the dashboard revealed that about five people complained about a fake sale in the last six months, and there was a sudden spike in product reviews quantifying a new product launch campaign effectiveness. This dashboard is developed using Angular and D3js
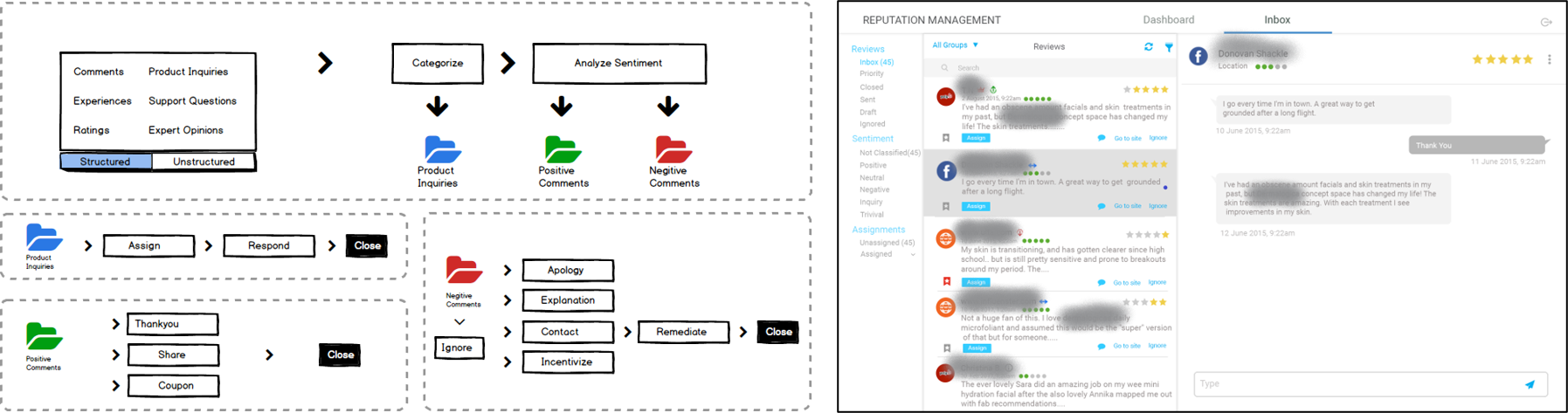
Research reports 1,2 suggest that online reviews impact 93% of purchase decisions, and businesses are not proactively soliciting consumers for reviews, even though most consumers are willing to give one. Reputation management has become an essential tool for businesses to increase sales and improve brand image. Provide a Reputation management tool that helps companies to
- Centralize consumer reviews.
- Quickly respond and remediate a consumer issue.
- Promptly respond to trade inquiries.
- Create tickets for reviews the require attention.
- Feed consumer feedback to product development teams
Consumer review analytics and consumer analytics currently exist in two different silos due to a lack of mapping logic - The majority of reviews disclose only the reviewer's name and location. Even though some companies have partial success in matching the name and the location, the gap remains significant. A syndicated approach to share reviewer details, after obtaining the reviewer's consent, with the product manufactures may resolve the issue in the future.
Properly matched consumer reviews will open doors for deep learning and classification algorithms. Some of them are.
- Customer Lifetime Value analysis results in accurate forecasting.
- Early detection of VIP customers and personalize their shopping experience.
- Optimize channel attribution.
- Reward Reviewers.
Conclusion
The paper outlined a quick and inexpensive method of extracting consumer emotions from reviews using N-gram models. Our experiments also reveal that the N-gram analyzer's positive emotions and Vader's positive sentiments are matching. In general, It takes about two weeks for a new market segment to generate trigram patterns for 40% analyzer accuracy and a month for 60% accuracy. Using Naïve Bayes, Maximum Entropy classification, Support Vector Machines(SVM), and Stanford NLP can further improve the model accuracy.
References
About Mobigesture
Mobigesture has delivered text mining and analytical data visualization solutions to customer care, skincare and hospitality industries. Our team is proficient in scraping spiders, cloud-native resources, back-office integrations, NLP, predictive & deep learning, big data, AWS, Azure, GCP, Python Django/Flask, NodeJS, MongoDB, Elastic Search, React, Angular, D3, and Mobile Hybrid frameworks.
For any demos or POCs, please write to us at contact@mobigesture.com and know more about our offerings.